Alpaca is a fine-tuned LLaMA model, designed to solve the lack of instruction-following capability of LLaMA models. This model architecture is the same as ChatGPT, but with slightly different weights, and it can follow conversations and instructions. The 7B and 13B Alpaca models are available.
Alpaca was trained to follow instructions like ChatGPT. The authors generated the training data using OpenAI’s GPT-3, then converted them to 52k instruction-following conversational data using the Self-Instruct pipeline. As a result, Alpaca is fine-tuned to respond to conversations like ChatGPT.
A blinded evaluation for instruction-following ability ranked the responses of Alpaca 7B and GPT-3 (text-davinci-003 specifically, which is also trained with instructions) roughly equally. However, this is just a narrow aspect of performance. It doesn’t mean Alpaca performs equally with GPT-3 in other areas like code generation and scientific knowledge, which were not tested in the study.
Instruction-following models such as GPT-3.5, ChatGPT, Claude, and Bing Chat have become increasingly powerful. However, despite their widespread deployment, they still have many deficiencies: they can generate false information, propagate social stereotypes, and produce toxic language.
To make maximum progress in addressing these pressing problems, it is important for the academic community to engage. Unfortunately, doing research on instruction-following models in academia has been difficult, as there is no easily accessible model that comes close in capabilities to closed-source models such as OpenAI’s text-davinci-003.
The Alpaca model provides a new option for researchers in this field. It is a fine-tuned LLaMA model that is surprisingly small and easy/cheap to reproduce, costing less than $600. The authors are releasing their training recipe and data, and intend to release the model weights in the future. They are also hosting an interactive demo to enable the research community to better understand the behaviour of Alpaca. Interaction can expose unexpected capabilities and failures, which will guide the future evaluation of these models. Users are also encouraged to report any concerning behaviours in the web demo so that the authors can better understand and mitigate these behaviours.
The Alpaca model is intended only for academic research, and any commercial use is prohibited. This is due to three factors: First, Alpaca is based on LLaMA, which has a non-commercial license. Second, the instruction data is based on OpenAI’s text-davinci-003, whose terms of use prohibit developing models that compete with OpenAI. Finally, the authors have not designed adequate safety measures, so Alpaca is not ready to be deployed for general use.
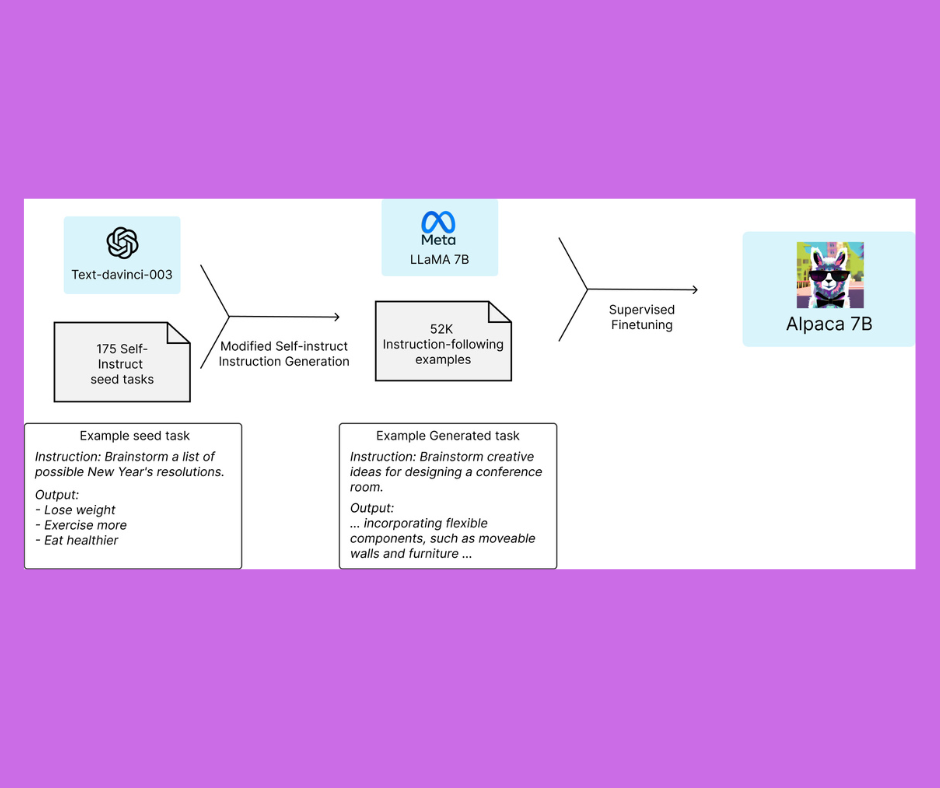
To train a high-quality instruction-following model under an academic budget, there are two important challenges: a strong pre-trained language model and high-quality instruction-following data. The first challenge is addressed with the recent release of Meta’s new LLaMA models. For the second challenge, the self-instruct paper suggests using an existing strong language model to automatically generate instruction data. In particular, Alpaca is a language model fine-tuned using supervised learning from a LLaMA 7B model on 52K instruction-following demonstrations generated from OpenAI’s text-davinci-003.
The authors started with the 175 human-written instruction-output pairs from the self-instruct seed set. They then prompted text-DaVinci-003 to generate more instructions using the seed set as in-context examples. They improved over the self-instruct method by simplifying the generation pipeline and significantly reduced the cost. Their data generation process resulted in 52K unique instructions and the corresponding outputs, which were then used to train a neural network model. The authors employed transfer learning and fine-tuned the GPT-3 language model on their instruction-output pairs to develop a specialized model for instruction generation.
The resulting model, named GPT-3-InstGen, was able to generate coherent and high-quality instructions for a wide range of tasks. The authors evaluated the model on a variety of benchmark datasets and found that it outperformed state-of-the-art models in terms of both quality and diversity of generated instructions. This work demonstrates the potential of transfer learning and fine-tuning for developing specialized language models that can perform complex tasks such as instruction generation.
Interesting Fact:
What is Alpaca? How is it different from a llama?
An Alpaca is a domesticated species of south american camelid, related to the llama and Vicuna. It is smaller than a llama and has finer and softer fleece. Alpacas are raised for their fleece, which is used to make knitted and woven garments.
Limitations and Risks
Alpaca is not ready for general use and is intended only for academic research. There are several reasons for this:
Non-commercial License: Alpaca is based on Meta's LLaMA models, which have a non-commercial license. As a result, any commercial use of Alpaca is prohibited.
Use of OpenAI's text-davinci-003: The instruction data used to train Alpaca is based on OpenAI's text-davinci-003, whose terms of use prohibit developing models that compete with OpenAI.
Lack of Safety Measures: Alpaca has not been designed with adequate safety measures and may generate toxic language or propagate social stereotypes. Therefore, it should not be deployed for general use.
Conclusion
Alpaca is a promising step towards fine-tuning language models for instruction-following. It is surprising to see that Alpaca, which is only 1/26th the size of text-davinci-003, can achieve similar results on single-turn instruction-following.
Read More:
 Rohan Taori*
Rohan Taori*
We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!