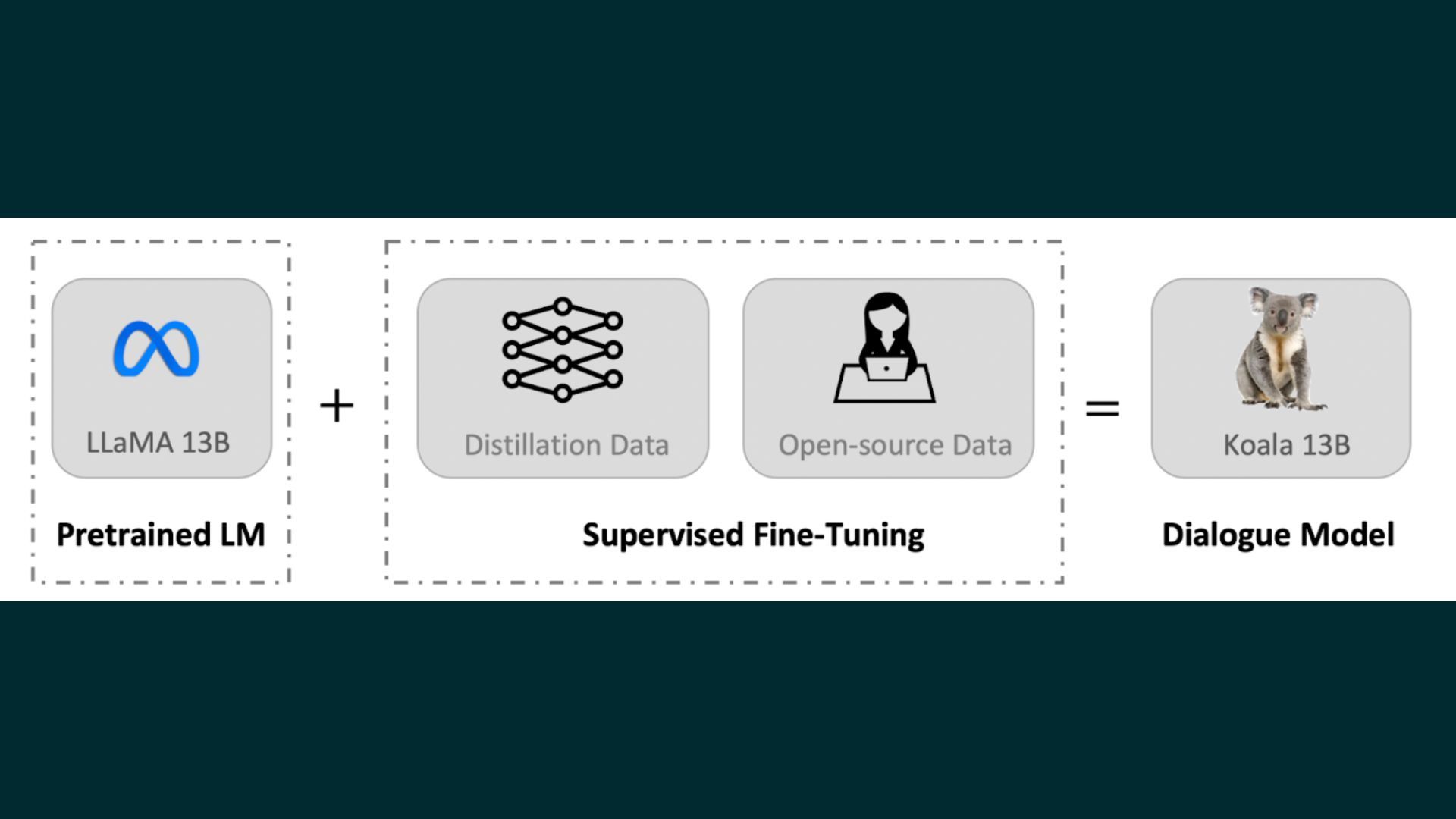



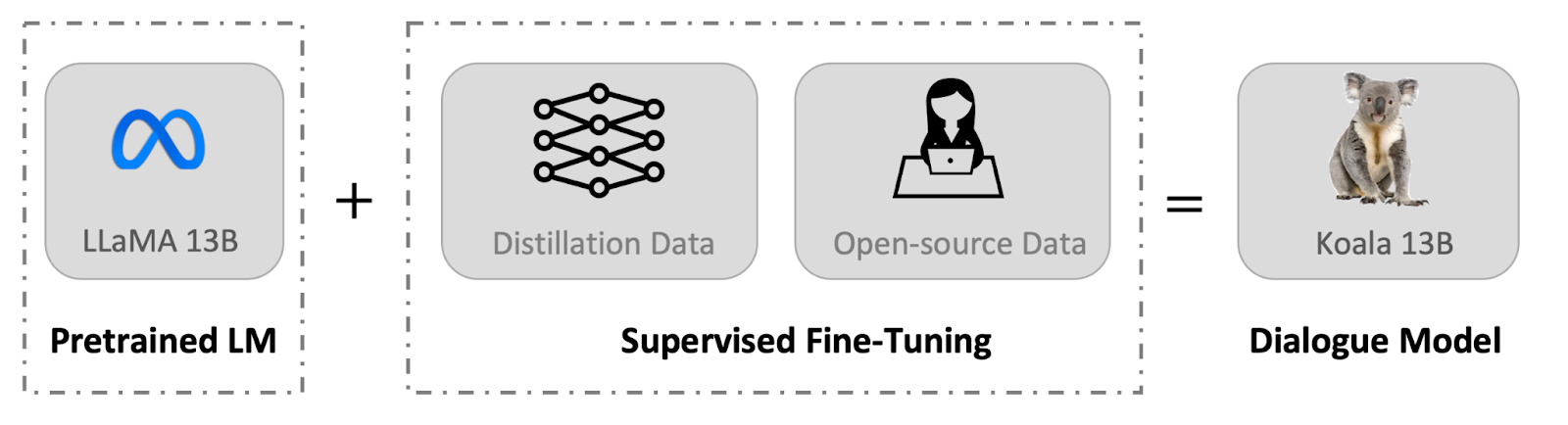
UC Berkeley has released a dialogue model for research purposes named Koala. Koala is a new chatbot model that uses freely available interaction data to achieve competitive performance with existing models. The model is fine-tuned on a base model called LLaMA, which is trained on dialogue data from the web and public datasets, including high-quality responses from other large language models.
The goal of Koala is to demonstrate that carefully selected training data can enable smaller open-source models to approach the performance of larger, closed-source models.Koala-13B is the resulting model, and it shows competitive performance as evaluated by human prompts.
The community should put more effort into curating high-quality datasets to enable safer, more factual, and more capable models in the future.
Researchers are encouraged to engage with Koala's system demo and report any alarming actions they observe to help improve the model's content, safety, and reliability.
Koala is a research prototype and should not be used outside of research. To build a dialogue model like Koala, it is important to have good training data.ChatGPT, Bard, Bing Chat, and Claude use proprietary datasets built using a lot of human annotation. Koala's training data were curated from the web and public datasets, including dialogues with existing language models like ChatGPT.
Koala focuses on collecting a small, high-quality dataset instead of scraping as much web data as possible. Koala's dataset includes public user-shared dialogues with ChatGPT and the human and ChatGPT responses from the HC3 English dataset. The dataset was curated carefully to ensure data quality and non-English conversations were removed.
The resulting dataset contains approximately 30,000 examples from ShareGPT and around 87,000 question-answer examples from HC3. Koala uses open-source datasets to train its dialogue model. The selected datasets include components from LAION's Open Instruction Generalist, Stanford Alpaca, Anthropic HH, OpenAI WebGPT, and OpenAI Summarization. The datasets have either single-turn question-answering or dialogue conversations, and some include human feedback. Koala conditioned its model on positive or negative markers depending on the preference label.
The model was implemented with JAX/Flax in EasyLM, Koala's open-source framework. The training of the model was done on a single Nvidia DGX server with 8 A100 GPUs and took 6 hours to complete for 2 epochs.
The training cost for such a run on public cloud computing platforms is typically less than $100 with preemptible instances.
Preliminary Evaluation
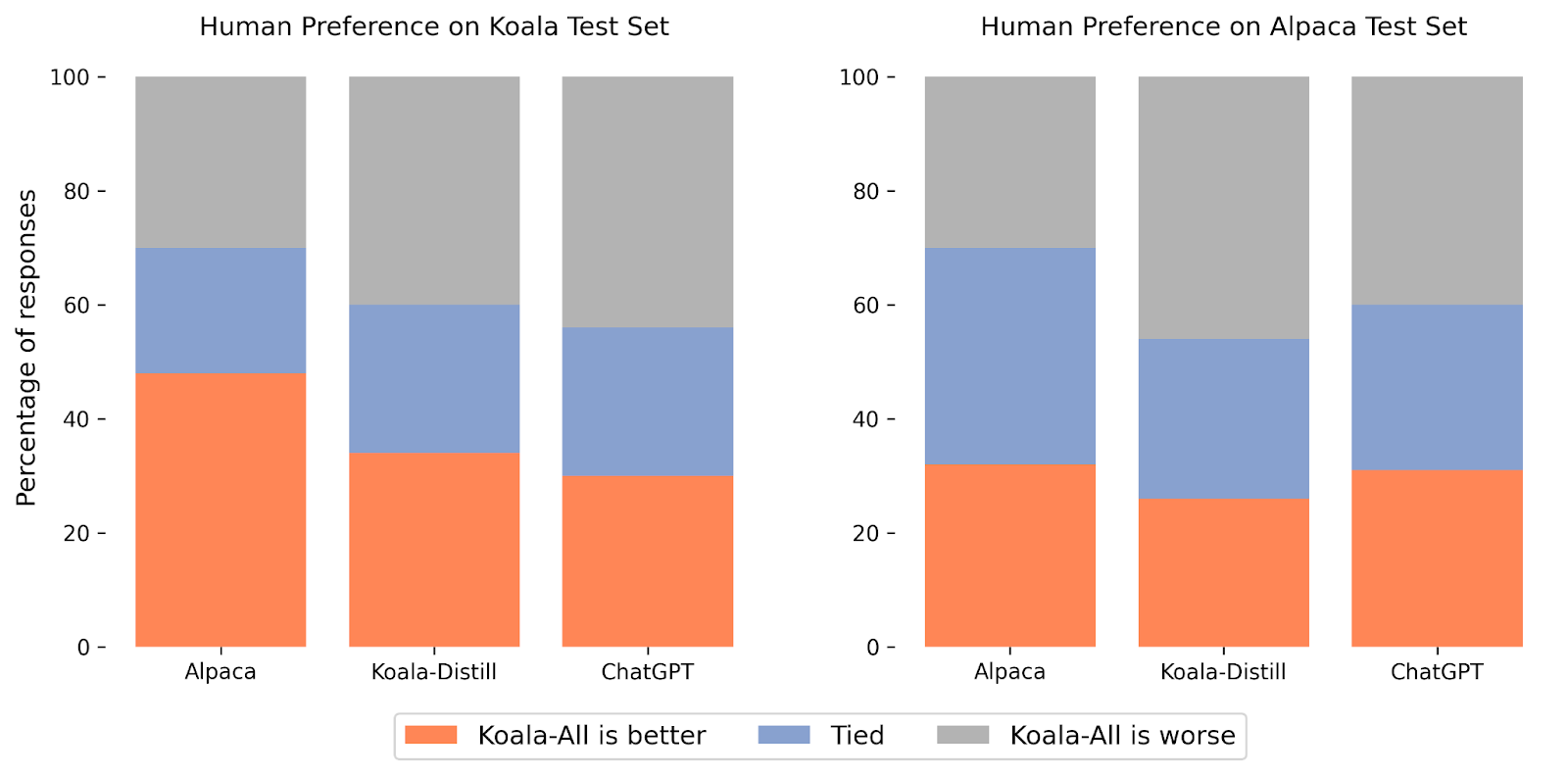
The research team conducted experiments to compare the performance of two models, Koala-Distill and Koala-All, to evaluate the influence of distillation and open-source datasets on final performance. They used two evaluation sets, the Alpaca Test Set consisting of 180 test queries used by Stanford’s Alpaca, and their own test set, the Koala Test Set, consisting of 180 real user queries that were posted online.
The team used a blind pairwise comparison approach and asked approximately 100 evaluators on the Amazon Mechanical Turk platform to compare the quality of model outputs on these held-out sets of prompts. The evaluators were presented with an input prompt and the output of two models and were asked to judge which output was better using criteria related to response quality and correctness.
On the Alpaca test set, Koala-All exhibited comparable performance to Alpaca. However, on their proposed test set, Koala-All was rated as better than Alpaca in nearly half the cases and exceeded or tied to Alpaca in 70% of the cases. This suggests that Koala would be expected to perform better in assistant-like applications.
The team also found that training on open-source data in addition to the distillation data (Koala-All) performs slightly worse than training on just ChatGPT distillation data (Koala-Distill). This suggests that effective instruction and assistant models could be finetuned from LLM backbones entirely using data from larger and more powerful models, so long as the prompts for these responses are representative of the kinds of prompts that users will provide at test time. The authors conclude that curating high-quality dialogue data that is diverse in user queries is the key to building strong dialogue models.
Future Work:
Koalas can be a useful platform for future academic research on large language models. It can be finetuned or utilized with more limited computing. Potentially promising research directions include language model safety, better alignment with human intentions, understanding model bias and spurious correlations, and making language models more interpretable.
The Team:
The Koala model is a joint effort across multiple research groups in the Berkeley Artificial Intelligence Research Lab (BAIR) of UC Berkeley.
Read More
We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!