Advancing Chatbot Evaluation
As the demand for conversational AI continues to soar, it becomes imperative to assess chatbots' capabilities accurately. These new additions to the Chatbot Arena leaderboard provide comprehensive metrics and improved models that push the boundaries of chatbot performance evaluation.
MT-Bench: Assessing Conversational Ability
MT-Bench is a meticulously curated benchmark comprising 80 high-quality, multi-turn questions. These questions are specifically designed to assess the flow of conversation and instruction comprehension in chatbots. By including both common use cases and challenging instructions, MT-Bench aims to differentiate chatbots based on their performance in multi-turn dialogues. Through the Chatbot Arena, we have collected valuable user prompts and crafted a diverse set of questions across multiple categories.
Evaluating Chatbot Performance with MT-Bench
To evaluate chatbot responses, researchers have turned to automated evaluation tools, such as GPT-4, to assess the performance of these conversational AI systems. In their study titled "Judging LLM-as-a-judge," the team explores the reliability of GPT-4 as an automated judge for chatbot evaluation. The study acknowledges certain limitations, including position bias and verbosity bias, which can affect the judgments made by the LLM judges.
However, to mitigate these biases and enhance the reliability of the evaluation process, the researchers have implemented various strategies. By leveraging techniques such as few-shot judge, chain-of-thought judge, reference-based judge, and fine-tuned judge, they aim to address the limitations and improve the accuracy of the evaluations conducted by GPT-4.
The findings of the study are promising. The results demonstrate that strong LLM judges, such as GPT-4, align remarkably well with human preferences, achieving an impressive agreement rate of over 80%. This high level of agreement indicates that the judgments made by GPT-4 closely match the evaluations made by human judges. Moreover, the study reveals that single-answer grading based on GPT-4 can effectively rank chatbot models and accurately reflect human preferences.
As the field of chatbot evaluation continues to evolve, researchers are actively exploring ways to refine the methodologies and address the challenges associated with assessing conversational AI systems. The insights gained from studies like "Judging LLM-as-a-judge" contribute to advancing the field, enabling researchers and developers to create more competent and user-centric chatbot models.
The Vicuna-33B Models: Enhanced Performance
In addition to MT-Bench, we are excited to introduce the Vicuna-33B models—a series of chatbot models with parameter sizes ranging from 7B to 33B. These models have been trained on an extended dataset of user-shared conversations, enabling them to provide enhanced performance and more accurate responses. The Vicuna-33B models are now available, and their weights can be accessed for further evaluation and utilization.
Results and Insights:
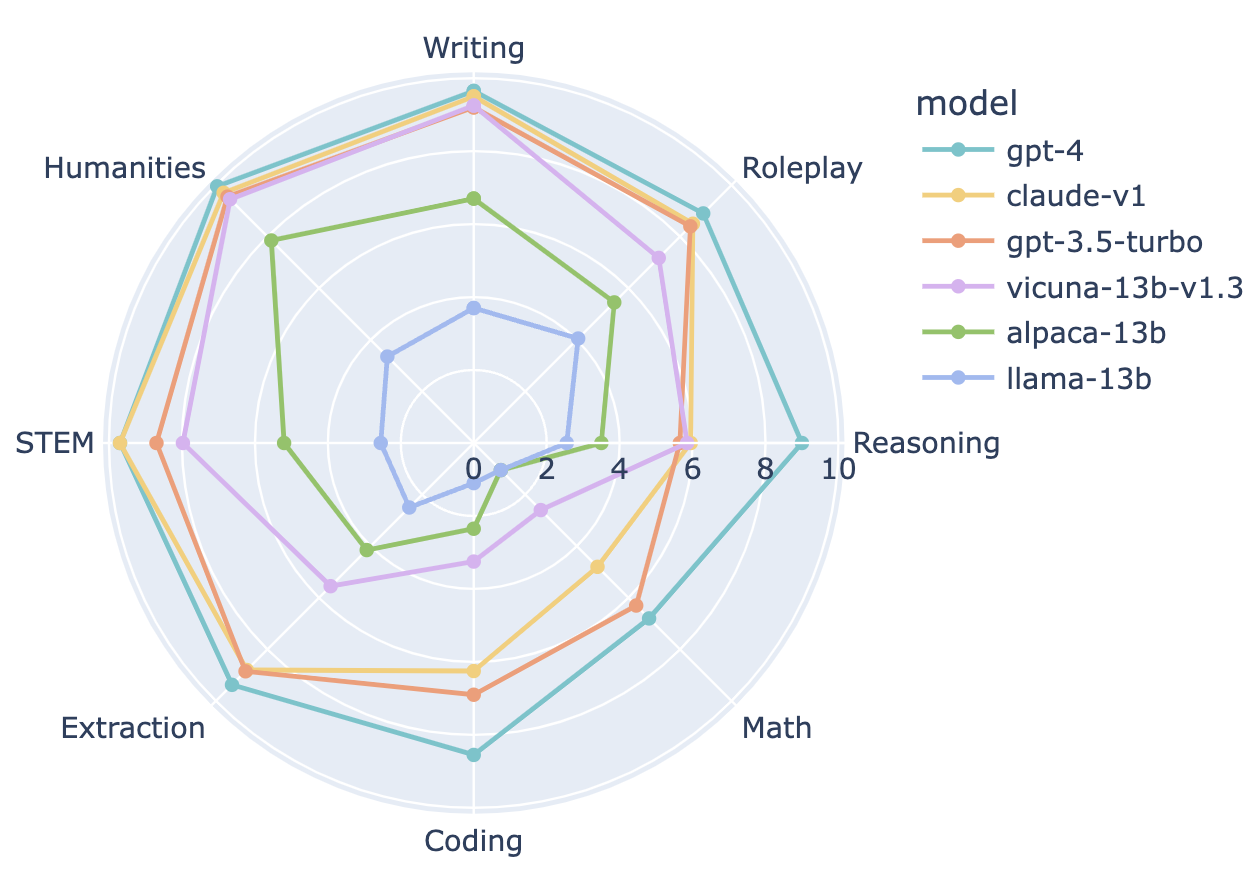
By evaluating 28 popular instruction-tuned models using MT-Bench, we observe significant performance gaps among chatbots. The scores obtained from MT-Bench exhibit a high correlation with the Chatbot Arena Elo rating, highlighting its effectiveness in distinguishing chatbots' capabilities. Furthermore, we delve into the performance breakdown of representative chatbots across different categories, shedding light on their strengths and areas for improvement.
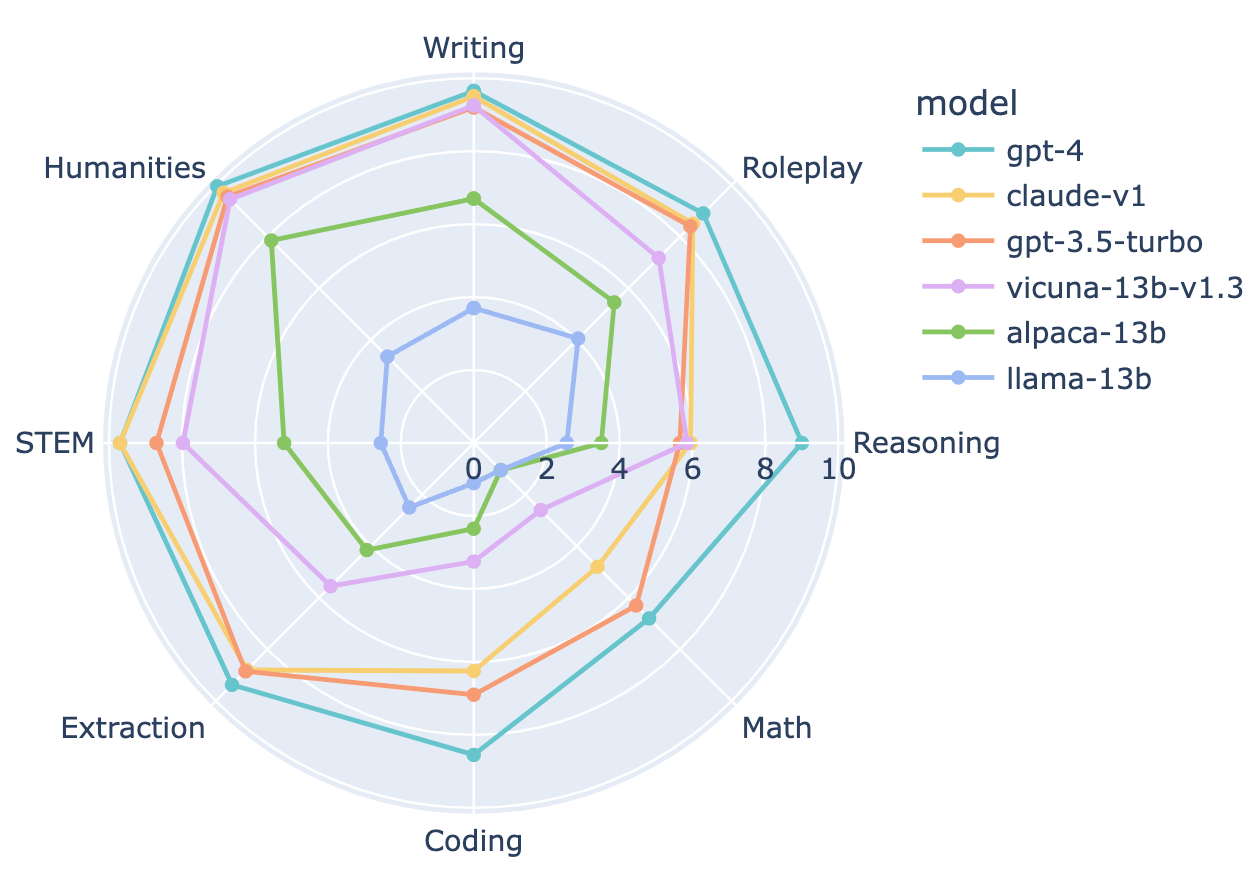
Advantages of MT-Bench and Future Developments:
MT-Bench offers scalability, category breakdowns, and explainability, providing valuable insights into chatbot performance. While utilizing LLM judges should be done with caution, the combination of MT-Bench and GPT-4 as an evaluation pipeline showcases promising results. We are actively expanding the MT-Bench question set to MT-Bench-1K, integrating high-quality prompts from the Chatbot Arena, and leveraging LLMs to generate new ones automatically. This expansion will further enhance the evaluation of chatbots' conversational abilities.
Multi-Turn Conversation Capabilities:
Analyzing the performance of selected models in multi-turn conversations provides valuable insights into their ability to maintain context and engage in extended dialogues. MT-Bench incorporates challenging follow-up questions, and open models experience a significant drop in performance from the first to the second turn. In contrast, strong proprietary models demonstrate consistency in their responses. Notably, there is a performance gap between models based on the LLaMA framework and those with permissive licenses. These findings emphasize the importance of assessing chatbot performance in multi-turn scenarios.
Explainability with LLM Judges
An advantage of utilizing LLM judges for evaluation is their ability to provide explainable feedback. GPT-4, in particular, offers comprehensive justifications for its judgments, aiding humans in making informed decisions. Our study reveals that these reviews are valuable in guiding human evaluators and establishing transparency in the evaluation process. Demonstrating the potential for explainability in LLM judges contributes to the ongoing research and development of reliable evaluation methodologies.
Future Perspectives:
In this blog post, we discovered about MT-Bench and Vicuna-33B as significant advancements in chatbot evaluation. MT-Bench addresses the limitations of traditional benchmarks by focusing on multi-turn conversations and instruction-following capabilities. The evaluation pipeline involving GPT-4 as an automated judge showcases promising results, providing scalable and explainable approximations of human preferences. Additionally, the Vicuna-33B models offer enhanced performance and improved responses, enabling chatbots to excel in real-world scenarios.
References:
- Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
- Can foundation models label data like humans?
- How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
- The False Promise of Imitating Proprietary LLMs
- AlpacaEval and AlpacaFarm
- Large Language Models are not Fair Evaluators
Links to tools and code:
- MT-bench: fastchat.llm_judge
- Arena Elo calculator
- MMLU: InstructEval and Chain-of-Thought Hub
Read More


We research, curate and publish daily updates from the field of AI. Paid subscription gives you access to paid articles, a platform to build your own generative AI tools, invitations to closed events and open-source tools.
Consider becoming a paying subscriber to get the latest!